Apache Flink is a stream processing framework, it is intended as a replacement for Apache Storm / Apache Spark. In this article I highlights some main features of Apache Flink with some very abstract introduction of usages.
Advantages with Apache Flink
- Realtime processing, just like Storm.
- Supports scaling, fault-tolerant and replay after crash.
- Each Flink node has local state access.
Data flow in Apache Flink
Flink logical topology is shown in the following image. Data read from TCP, file, Kafka or even database to a Flink source node, streaming processed in Flink nodes and finally sent to Flink sink node, all in real time. Note that the operator can and usually have multiple layers and each layer can also includes multiple operator nodes.

Data exchange strategies
Data exchange strategies manages how tasks would be distributed to the next layer of operators. Flink supports the following strategies,
- simple forward
- broadcast
- key-based
- random
Data transformation
Note all Flink functions must be Java serializable. This requirement comes from the fact that Flink functions will be serialized and sent to other nodes in the cluster.
Flink operator supports the following data transformation operations.
- rolling aggregation
- window operation by
- session
- fixed size
- sliding window
Time in Flink
Data transformations relies on timestamp. You can use two types of time in Flink:
- Event time which is the timestamp in client side, e.g., where the event or message originates.
- Process time which is the timestamp on Flink node.
Stream transformations
Stream transformation in operator nodes are similar to the functions very common in functional programming.
map, filter, flatMapkeyBy: partition stream by selector, here are some exampleskeyBy(0, 2)takes the first and third values of a tuple as keykeyBy("2")takes the second values of a tuple as keykeyBy("person.address")takes value from a nested object as key
reduce, sum, min, max, minBy, maxBy: These transformations can only be applied to bounded data domain, usually after rolling or window aggregation.union: merging multiple streamssplit: split a stream to multiple streams- And for data distribution:
shufflerebalancerescale: applicable if number of senders largely differs from number of receiversbroadcastglobalpartitionCustom: use your own customized distribution function
Data serialization in Flink
Flink can hanle serialization of basic Java data types, Flink tuples and POJO / Avro types, you can find the supported types in org.apache.flink.api.common.typeinfo.Types. As a configurable fallback, Kryo is used to serialize other data types.
Parallelism
To configure parallelism of a task, use the setParallelism method after a task,
// Get default parallelism, which equals the number of CPU cores,
var defaultP = env.getParallelism;
stream
.map(new MyMapper).setParallelism(defaultP * 2);
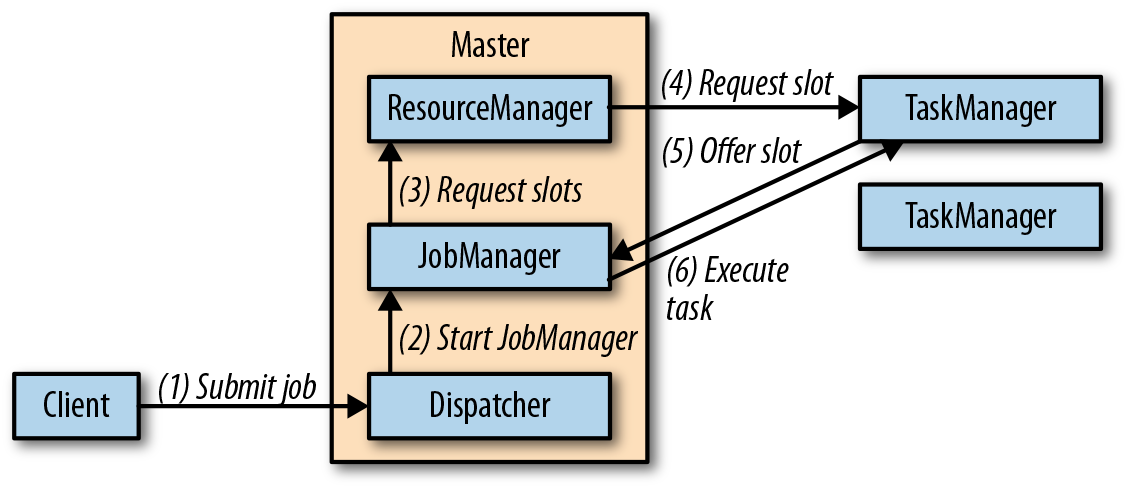
Deployment
You can choose one of the following deployment modes:
- standalone cluster
- docker
- Hadoop YARN
- Kubernetes
The following figure shows how a job get executed in a standalone cluster deployment.